The majority of code and analysis in this post was originally written back in mid-2018 (in this notebook). I’ve consolidated some cells, automated data retrieval, and added cell labels to make things render nicely, but otherwise I’ve left the work as-is. Compared to my current work products, this old code is very messy and unpolished, but like Eric Ma (creator of the networkx graph data analysis package), I believe in showing newer data analysts and scientists I mentor that no one in this field started off with mastery of git, pandas, bash, etc, and that everyone who lasts loves to keep learning and improving.
After I integrate these old posts into this blog, I’ll write an EDA post that starts from scratch using up-to-date data.
1 Exploration in Criminal Justice and Corrections Data
I’ve repeatedly read the statistic that the US makes up around 4% of the global population, but makes up more than 20% of the prison population. Well defined questions are crucial tools for making sense of raw data, and this massive asymmetry is provokes some important questions, such as those listed below.
Why isn’t our prison population proportional to our regular population?
Do other countries have fewer criminals?
Do we have a drastically different approach to criminal justice than the rest of the world?
Are our prison sentences just much longer?
What are the most common crimes?
How many people are in for those crimes?
How many people enter the prison system each month?
How many exit?
Recidivism
How many prisoners have been to prison at least once before?
What is the recidivism rate for 1st time prisoners who served in public prisons?
With some questions in hand, I can start trying to gather data that could shed light on the situation. I may not be able to get data with the resolution needed to answer some of these questions (e.g. I may not be able to find data broken down by month).
The government makes some data publicly available. While government data is rarely current, often involves a bit of cleanup, and always involves hunting through old government sites, it’s the only source for much of this extremely valuable information. From the Bureau of Justice Statistics, I found a government project called the Prisoner Series and I downloaded the most recent data.
Imports, styling, and path definition
import osfrom urllib.request import urlretrieveimport pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.ticker as tickerfrom IPython.core.display import display, HTML%matplotlib inline# Notebook Stylingpd.options.display.float_format =lambda x: "%.5f"% xpd.options.display.max_columns =Noneplt.rcParams['figure.figsize'] =10,10DATA_DIR_PATH = os.path.join('data', 'prison')os.makedirs(DATA_DIR_PATH, exist_ok=True)@ticker.FuncFormatterdef y_formatter(x, pos):return'{:4.0f}'.format(x/1000)
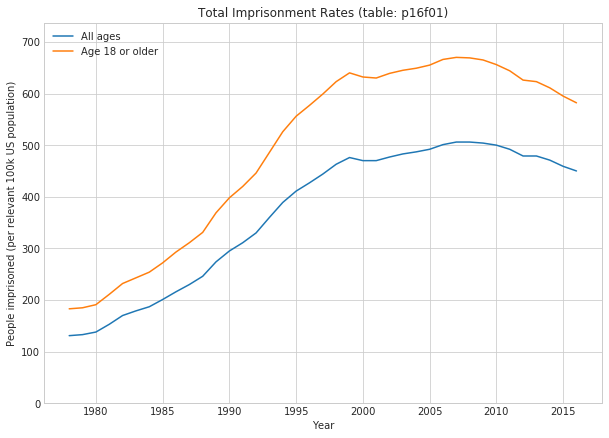
1.3 Total Imprisonment Rates (Table p16f01)
The values in the by-race dataset are [per 100k population].
Downloading the relevant data and unzipping it
import zipfileimport requestsurl ="https://bjs.ojp.gov/redirect-legacy/content/pub/sheets/p16.zip"file_path = os.path.join(DATA_DIR_PATH, "p16.zip")headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}ifnot os.path.isfile(file_path): response = requests.get(url, headers=headers, stream=True)if response.status_code ==200:withopen(file_path, "wb") asfile:for chunk in response.iter_content(chunk_size=1024):if chunk:file.write(chunk)with zipfile.ZipFile(file_path, 'r') as zf: zf.extractall(DATA_DIR_PATH)
Loading and preprocessing the f01 dataset, Total Counts
with sns.axes_style("whitegrid"): fig, ax = plt.subplots(figsize=(10,7)) ax.plot(total_df['All ages']) ax.plot(total_df['Age 18 or older']) ax.set_title('Total Imprisonment Rates (table: p16f01)') ax.set_xlabel('Year') ax.set_ylabel('People imprisoned (per relevant 100k US population)') ax.legend() ax.set_ylim([0, 1.1*max([total_df['All ages'].max(), total_df['Age 18 or older'].max()])])
1.4 Observations
The imprisonment rate normalized to the entire population of US residents is lower than the imprisonment rate normalized to the population of US residents that are 18 or older. This indicates that the imprisonment rate for people under age 18 is much lower than for people 18 or older. That fits with my intuition.
We also see that the imprisonment rate climbs steadily from 1980 up through 1999, dips, and peaks around 2007-2008, at which point it starts trending down. In 1978, 183 people were in prison per every 100k US residents 18 or older. In 2007, 670 people were in prison per every 100k US residents 18 or older. That’s a 266% increase in the imprisonment rate over that 29 year span. That’s huge.
1.4.1 New Questions:
What was responsible for the increase in the rate of imprisonment? What was responsible for the decrease?
Was it proportional to the actual crime rates?
Was it a product of different enforcement policies?
To answer these new questions, we will probably have to look at other sets of data.
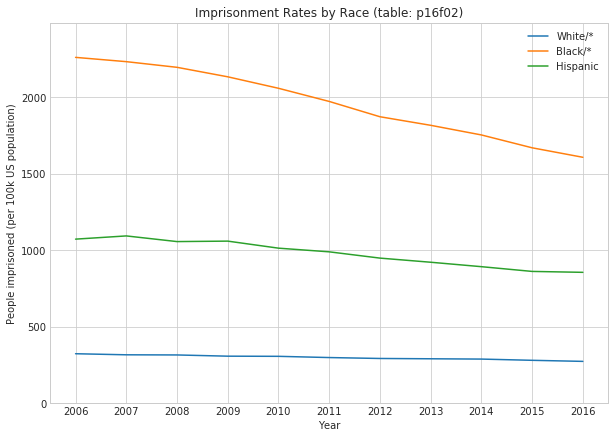
1.5 Imprisonment by Race (Table p16f02)
Imprisonment rate of sentenced prisoners under the jurisdiction of state or federal correctional authorities, per 100,000 U.S. residents age 18 or older, by race and Hispanic origin, December 31, 2006–2016
Loading and preprocessing the f02 data, Counts by Race
with sns.axes_style("whitegrid"): fig, ax = plt.subplots(figsize=(10,7)) ax.plot(race_df['White/*']) ax.plot(race_df['Black/*']) ax.plot(race_df['Hispanic']) ax.set_title('Imprisonment Rates by Race (table: p16f02)') ax.set_xlabel('Year') ax.set_ylabel('People imprisoned (per 100k US population)') ax.legend() ax.set_ylim([0, 1.1*max([race_df['White/*'].max(), race_df['Black/*'].max(), race_df['Hispanic'].max()])])
Printing out summary stats for f02 data, Counts by Race
print('{:>8s} imprisonment per 100k US pop: max: {}, min: {}' .format('White/*', race_df['White/*'].max(), race_df['White/*'].min()))print('{:>8s} imprisonment per 100k US pop: max: {}, min: {}' .format('Black/*', race_df['Black/*'].max(), race_df['Black/*'].min()))print('{:>8s} imprisonment per 100k US pop: max: {}, min: {}' .format('Hispanic', race_df['Hispanic'].max(), race_df['Hispanic'].min()))print('*: non-Hispanic')
White/* imprisonment per 100k US pop: max: 324.0, min: 274.0
Black/* imprisonment per 100k US pop: max: 2261.0, min: 1608.0
Hispanic imprisonment per 100k US pop: max: 1094.0, min: 856.0
*: non-Hispanic
1.6 Observations
This is very striking. We see that there is a very significant difference in the rates of white (non-Hispanic), black (non-Hispanic), and Hispanic imprisonment. We also see that rates for all three have dropped over this time period.
1.6.1 New Questions:
What is responsible for this difference in imprisonment rates for different demographic groups?
Based on prior research, I suspect that this is the result of many systemic factors, but let’s continue exploring the data.
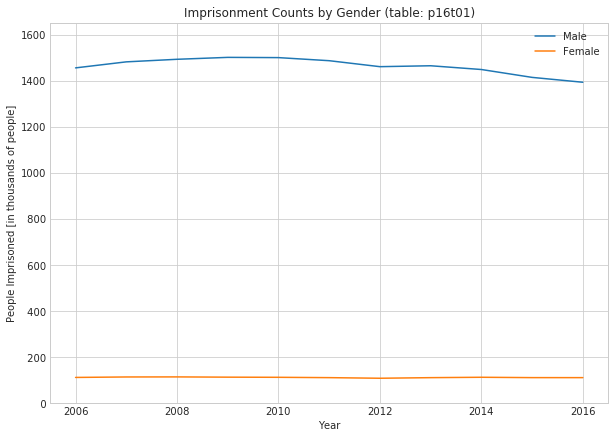
1.7 Breakdown by Gender (Table p16t01)
Loading and preprocessing the t01 data, Total Counts by Gender and State/Federal
with sns.axes_style("whitegrid"): fig, ax = plt.subplots(figsize=(10,7)) ax.plot(sex_df['Male']) ax.plot(sex_df['Female']) ax.set_title('Imprisonment Counts by Gender (table: p16t01)') ax.set_xlabel('Year') ax.yaxis.set_major_formatter(y_formatter) ax.set_ylabel('People Imprisoned [in thousands of people]') ax.legend() ax.set_ylim([0, 1.1*max(sex_df['Male'].max(), sex_df['Female'].max())])
1.8 Observations
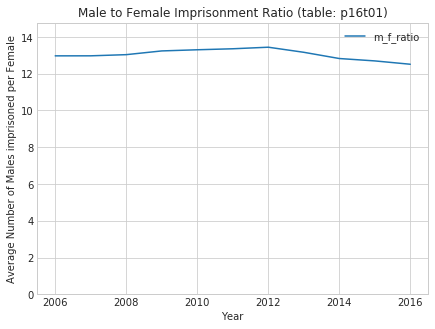
The first thing that I notice is that the number of men in prison is much higher than the number of females imprisoned. Per the chart below, over the entire span of the data set (2006 to 2016), there are at least 12 men in prison for each woman in prison. This is a massive asymmetry. It doesn’t feel very controversial, but should it? According to the 2010 US Census, the US population is 50.8% female and 49.2% male.
1.8.1 New Questions
Why are men so much more likely to be in prison?
What are the relevant differences between men and women?
What is the gender breakdown of crimes?
Plotting out Male to Female imprisonment ratio
sex_df['m_f_ratio'] = sex_df['Male'] / sex_df['Female']with sns.axes_style("whitegrid"): fig, ax = plt.subplots(figsize=(7,5)) ax.plot(sex_df['m_f_ratio']) ax.set_title('Male to Female Imprisonment Ratio (table: p16t01)') ax.set_xlabel('Year') ax.set_ylabel('Average Number of Males imprisoned per Female') ax.legend() ax.set_ylim([0, 1.1*sex_df['m_f_ratio'].max()])
Plotting out Counts of State and Federal imprisonment
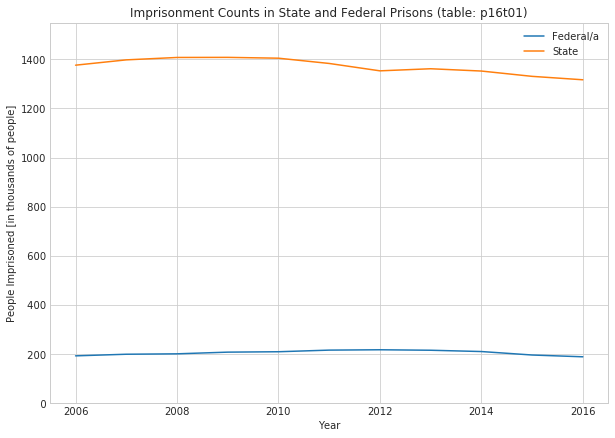
with sns.axes_style("whitegrid"): fig, ax = plt.subplots(figsize=(10,7)) ax.plot(sex_df['Federal/a']) ax.plot(sex_df['State']) ax.set_title('Imprisonment Counts in State and Federal Prisons (table: p16t01)') ax.set_xlabel('Year') ax.yaxis.set_major_formatter(y_formatter) ax.set_ylabel('People Imprisoned [in thousands of people]') ax.legend() ax.set_ylim([0, 1.1*max(sex_df['Federal/a'].max(), sex_df['State'].max())])
1.8.2 Observations
Far more people are in State prisons than are in Federal prisons. That isn’t very controversial and at this level, I won’t dig much deeper. It may be interesting to dig further into imprisonment counts broken down by state.
2 To Be Continued
There are still 20 more tables that I haven’t looked at yet, but so far, we’ve seen * The imprisonment rates increased by just over 266% between 1978 and 2007. * Black people are imprisoned at a far higher rate than either Hispanic people or non-Hispanic white people. * Hispanic people are imprisoned at a far higher rate than non-Hispanic white people. * Far more men are imprisoned than women. * Far more people are in state prisons than in federal prisons.